Quartz
1. 前置知识
1.1. 任务调度思路
小顶堆
堆使用二叉树实现。小顶堆是完全二叉树且根总比叶子小的二叉树。
插入:后插冒泡。
取出:取根结点,最后一个叶子结点移动到根结点再下沉(冒泡的逆序)。
在Java中,操作需要依靠数组进行实现。
缺点:所以在实际运行的过程中,只适合任务量较少的情况。
时间轮
有点像钟表,假设有12个刻度,则在每个刻度上都挂着一个链表。依次执行。
缺点:维度如果多起来,刻度会越多(爆炸),性能越差。
分层轮
cron表达式也是这个思想,不同维度有不同的轮,可以解决维度爆炸的问题。最常用。
1.2. Timer
- Timer属于JDK自带的任务调度API。
- 使用小顶堆,实际上维护的是一个队列(Queue)。对小顶堆的根节点出队列(min),然后重新计算下次执行时间入队列。
- Timer的shedule是真正的执行时间,取决于上一个任务的结束时间而执行(如果上一个任务的结束时间超过触发的时间,会导致少执行次数),其中nextExecuteTime是预设的执行时间。sheduleAtFixedRate严格按照预设的时间(导致上一个任务没有运行结束而再次执行,从而导致执行顺序乱)。
- 会单线程方式进行运行,很可能导致任务阻塞。
- 运行时异常会导致timer线程中止。
1.3. 定时任务线程池
ScheduledExecutorService。可以理解成为Timer创建了多个线程池。
2. Quartz框架
2.1. 运行环境
- 嵌入在另一个独立式应用程序。
- 在应用程序服务器或Servlet容器内被实例化,且参与事务。
- 作为独立程序运行。
- 被实例化,作为独立的项目集群,用于作业的执行。
2.2. 概念
Quartz是一个基于Java实现的任务调度(Job scheduling)的调度中间件,属于OpenSymphony开源组织。
其使用建造者模式(链式编程),工厂模式(Factory)以及组件模式实现。
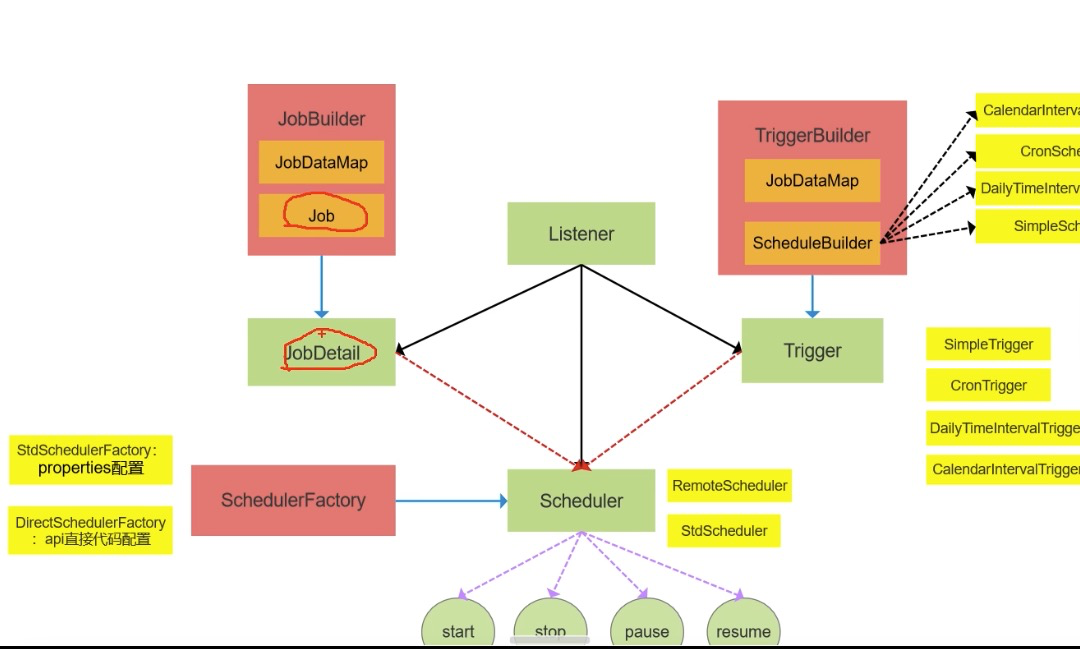
Scheduler - 任务调度器,会将任务JobDetail 和触发器Trigger整合起来。是与调度程序交互的主要API。
Scheduler的默认创建方式:工厂模式。默认工厂:StdSchedulerFactory。
SchedulerFactory schedulerFactory = new StdSchedulerFactory(); Scheduler scheduler = schedulerFactory.getScheduler();Job - 想要调度器执行的任务组件需要实现的接口,其中只有一个execute(JobExecutionContext context)方法,里面存放需要执行任务的内容。
JobExecutionContext - 存在于Job接口的execute方法的形参中。透过此对象可以访问到Quartz运行时环境以及JobDataMap、Scheduler、JobDetail、Trigger、上下次执行时间等数据。
JobDetail - 用于定义作业的实例,使用时会将Job的class对象放入这个实例中。
Trigger(即触发器) - 定义执行给定作业的计划的组件。用来触发执行Job的。
较常用由SimpleTrigger和CronTrigger两种。
SimpleTrigger
SimpleTrigger的属性包括:开始时间、结束时间、重复次数以及重复的间隔。
.withSchedule(SimpleScheduleBuilder.simpleSchedule() .withIntervalInSeconds(10) .withRepeatCount(10))CronTrigger
.withSchedule(CronScheduleBuilder.cronSchedule("0/5 * * 6 4 ?")) // 定义表达式
Trigger中,可以使用Quartz的Calendar对象的一些类来排除一些触发的时间。
HolidayCalendar cal = new HolidayCalendar(); cal.addExcludedDate( someDate ); cal.addExcludedDate( someOtherDate ); scheduled.addCalendar("myHolidays", cal, false);可以设置优先级
如果scheduler关闭了,或者Quartz线程池中没有可用的线程来执行job,此时持久性的trigger就会错过(miss)其触发时间,即错过触发(misfire)。不同类型的trigger,有不同的misfire机制。它们默认都使用“智能机制(smart policy)”,即根据trigger的类型和配置动态调整行为。当scheduler启动的时候,查询所有错过触发(misfire)的持久性trigger。然后根据它们各自的misfire机制更新trigger的信息。
所有的trigger都有一个Trigger.MISFIRE_INSTRUCTION_SMART_POLICY策略可以使用,该策略也是所有trigger的默认策略。
SimpleTrigger的Misfire策略常量
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY MISFIRE_INSTRUCTION_FIRE_NOW MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_EXISTING_REPEAT_COUNT MISFIRE_INSTRUCTION_RESCHEDULE_NOW_WITH_REMAINING_REPEAT_COUNT MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_REMAINING_COUNT MISFIRE_INSTRUCTION_RESCHEDULE_NEXT_WITH_EXISTING_COUNT.withSchedule(simpleSchedule() .withIntervalInMinutes(5) .repeatForever() .withMisfireHandlingInstructionNextWithExistingCount()SimpleTrigger的Misfire策略常量
MISFIRE_INSTRUCTION_IGNORE_MISFIRE_POLICY MISFIRE_INSTRUCTION_DO_NOTHING MISFIRE_INSTRUCTION_FIRE_NOW.withSchedule(cronSchedule("0 0/2 8-17 * * ?") .withMisfireHandlingInstructionFireAndProceed()
JobDataMap - 可以包含不限量的(序列化)的数据对象,方便获取。在Job实例执行的时候,可以使用其中的数据。JobDataMap是java.util.Map接口的一个实现,额外增加了一些便于存取基本类型的数据的方法。
可以使用 JobExecutionContext 的getMergedJobDataMap()方法获取到 Job 和 Trigger级的并集的 map 中的值。
JobBuilder - 用于定义/构建 JobDetail 实例,用于定义作业的实例。
TriggerBuilder - 用于定义/构建触发器实例。
SchedulerListener、TriggerListener、JobListener用于对Scheduler、Trigger、Job组件进行监听。
2.3. 简单入门
导坐标
<!-- https://mvnrepository.com/artifact/org.quartz-scheduler/quartz --> <dependency> <groupId>org.quartz-scheduler</groupId> <artifactId>quartz</artifactId> <version>2.3.2</version> </dependency> <!-- https://mvnrepository.com/artifact/junit/junit --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.13.2</version> <scope>test</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 --> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>2.0.0-alpha7</version> <type>pom</type> <scope>test</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-core --> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.17.2</version> </dependency>log4j.properties
### direct log messages to stdout ### log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=System.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n ### direct messages to file mylog.log ### log4j.appender.file=org.apache.log4j.FileAppender log4j.appender.file.File=/usr/admin/Desktop/mylog.log log4j.appender.file.layout=org.apache.log4j.PatternLayout log4j.appender.file.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n log4j.rootLogger=info, stdout编写一个类实现Job接口,并实现其execute方法
/** * 定义任务类 */ public class TestJob implements Job { private static final Logger log = LoggerFactory.getLogger(TestJob.class); @Override public void execute(JobExecutionContext context) throws JobExecutionException { // 这里放入要执行的任务 log.info("Test"); } }创建JobDetail,Trigger,Scheduler用以执行任务。
public class TestSchedulerDemo { public static void main(String[] args) throws Exception { // 1:从工厂中获取任务调度的实例 Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler(); // 2:定义一个任务调度实例,将该实例与TestJob绑定,任务类需要实现Job接口 JobDetail job = JobBuilder.newJob(TestJob.class) .withIdentity("job1", "group1") // 定义该实例唯一标识 .build(); // 3:定义触发器 ,马上执行, 然后每5秒重复执行一次 Trigger trigger = TriggerBuilder.newTrigger() .withIdentity("trigger1", "group1") // 定义该实例唯一标识 .startNow() // 马上执行 .withSchedule(SimpleScheduleBuilder.simpleSchedule() .repeatSecondlyForever(5)) // 每5秒执行一次 .build(); // 4:使用触发器调度任务的执行 scheduler.scheduleJob(job, trigger); // 5:开启 scheduler.start(); // 关闭 // scheduler.shutdown(); } }
2.4. 相关注解
- @DisallowConcurrentExecution:禁止并发地执行同一个Job定义(JobDetail定义)的多个实例。
- @PersistJobDataAfterExecution:持久化JobDetail中的DataMap(对Trigger中的DataMap无效)。如果一个任务不是持久化的,则当没有触发器关联它的时候,Quartz会从scheduler中删除它。
二者被推荐同时使用。
2.5. 注意点
Scheduler 的生命期,从 SchedulerFactory 创建它时开始,到 Scheduler 调用shutdown() 方法时结束;Scheduler 被创建后,可以增加、删除和列举 Job 和 Trigger,以及执行其它与调度相关的操作(如暂停 Trigger)。但是,Scheduler 只有在调用 start() 方法后,才会真正地触发 Trigger (即执行 Job)。除此之外,其还有常见的start、standby、shutdown操控方法来操纵触发器执行、挂起和关闭。
scheduler.start(); scheduler.standby(); shutdown(true) // 等待所有正在执行的job执行完毕后再关闭Scheduler shutdown(false): // 表示直接关闭SchedulerScheduler被停止后,会销毁了为Scheduler创建的所有资源(线程,数据库连接等资源),这个时候除非重新实例化,否则不能重新启动。只有处于start状态的时候,Trigger才会触发Job执行。
Job的一个 Trigger 被触发后,execute() 方法会被 scheduler 的一个工作线程调用;传递给 execute() 方法的 JobExecutionContext 对象中保存着该 job 运行时的一些信息 ,执行 job 的 scheduler 的引用,触发 job 的 trigger 的引用,JobDetail 对象引用,以及一些其它信息。
每个Job实例和JobDetail在每次执行的时候都会创建一个新的实例(Job需要有无参构造器,通过newInstance()方法调用),调用完成后,关联的实例会被释放,释放的实例会被垃圾回收机制回收。
setJobData和usingJobData的区别:
//JobBuilder /** * Add all the data from the given {@link JobDataMap} to the * {@code JobDetail}'s {@code JobDataMap}. * * @return the updated JobBuilder * @see JobDetail#getJobDataMap() */ public JobBuilder usingJobData(JobDataMap newJobDataMap) { jobDataMap.putAll(newJobDataMap); return this; } /** * Replace the {@code JobDetail}'s {@link JobDataMap} with the * given {@code JobDataMap}. * * @return the updated JobBuilder * @see JobDetail#getJobDataMap() */ public JobBuilder setJobData(JobDataMap newJobDataMap) { jobDataMap = newJobDataMap; return this; } // TriggerBuilder中,没有setJobData方法。set方法会替换整个dataMap,using方法会进行添加合并。
多触发器可以指向同一个作业,但单个触发器只能指向一个作业。
在Job实现类中添加成员变量以及其对应的setter方法,变量名为JobDataMap的key,则在初始化Job实现类的时候会自动调用setter方法注入JobDataMap对应的值。
private String message; public void setMessage(String message) { this.message = message; }usingJobData("message", "消息")scheduler.scheduleJob(job, trigger)有返回值,其返回值是调度器开始的时间。JobDetail和Trigger都有group和name属性,用以组成JobKey或者TriggerKey。如果二者均缺失,则会自动生成一个随机且唯一的JobKey或者TriggerKey。
/** * Use a <code>JobKey</code> with the given name and group to * identify the JobDetail. * * <p>If none of the 'withIdentity' methods are set on the JobBuilder, * then a random, unique JobKey will be generated.</p> * * @param name the name element for the Job's JobKey * @param group the group element for the Job's JobKey * @return the updated JobBuilder * @see JobKey * @see JobDetail#getKey() */ public JobBuilder withIdentity(String name, String group) { key = new JobKey(name, group); return this; } /** * Use a TriggerKey with the given name and group to * identify the Trigger. * * <p>If none of the 'withIdentity' methods are set on the TriggerBuilder, * then a random, unique TriggerKey will be generated.</p> * * @param name the name element for the Trigger's TriggerKey * @param group the group element for the Trigger's TriggerKey * @return the updated TriggerBuilder * @see TriggerKey * @see Trigger#getKey() */ public TriggerBuilder<T> withIdentity(String name, String group) { key = new TriggerKey(name, group); return this; }其中,group可以用来获取其下的所有name集合。
GroupMatcher<JobKey> gm = GroupMatcher.groupEquals("job-group"); Set<JobKey> set = scheduler.getJobKeys(gm);在Job执行时,JobExecutionContext中的JobDataMap为我们提供了很多的便利。它是JobDetail中的JobDataMap和Trigger中的JobDataMap的并集,但是如果存在相同的数据,则后者会覆盖前者的值。
Durability:如果一个job是非持久的,当没有活跃的trigger与之关联的时候,会被自动地从scheduler中删除。也就是说,非持久的job的生命期是由trigger的存在与否决定的。
RequestsRecovery:如果一个job是可恢复的,并且在其执行的时候,scheduler发生硬关闭(hard shutdown)(比如运行的进程崩溃了,或者关机了),则当scheduler重新启动的时候,该job会被重新执行。此时,该job的JobExecutionContext.isRecovering() 返回true。
Job接口的execute方法会抛出一个JobExecutionException异常,换句话说就是默认情况下该部分的异常会被quartz接管。所以可以将方法内的内容用try-catch包装起来,并且了解JobExecutionException部分,以便更好地处理异常。
缺省状态下,默认的group名为DEFAULT
/** * The default group for scheduling entities, with the value "DEFAULT". */ public static final String DEFAULT_GROUP = "DEFAULT"; public Key(String name, String group) { if(name == null) throw new IllegalArgumentException("Name cannot be null."); this.name = name; if(group != null) this.group = group; else this.group = DEFAULT_GROUP; }group和name都存放于Key的实现类中。
贴出其对比和自动创建名称的方法
public int compareTo(Key<T> o) { if(group.equals(DEFAULT_GROUP) && !o.group.equals(DEFAULT_GROUP)) return -1; if(!group.equals(DEFAULT_GROUP) && o.group.equals(DEFAULT_GROUP)) return 1; int r = group.compareTo(o.getGroup()); if(r != 0) return r; return name.compareTo(o.getName()); } public static String createUniqueName(String group) { if(group == null) group = DEFAULT_GROUP; String n1 = UUID.randomUUID().toString(); String n2 = UUID.nameUUIDFromBytes(group.getBytes()).toString(); return String.format("%s-%s", n2.substring(24), n1); }在触发器shutdown()之前,Job和Trigger可以在任何时候对Scheduler进行添加或删除。
2.6. 属性
以下配置摘自源码。
# 调度器实例名,用以区分调度器实例
org.quartz.scheduler.instanceName = DefaultQuartzScheduler
# IMPORTANT TO LEAVE THIS ON FOR THE CONTAINER TESTS (we want to know if the beans can be registered)
org.quartz.scheduler.jmx.export = true
# 自动生成instanceId
# org.quartz.scheduler.instanceId和instanceName不同的是必须在所有调度器实例中(集群中)唯一
# 如果运行在非集群环境中,自动产生的值是NON_CLUSTERED
org.quartz.scheduler.instanceId = AUTO
org.quartz.scheduler.rmi.export = false
org.quartz.scheduler.rmi.proxy = false
org.quartz.scheduler.wrapJobExecutionInUserTransaction = false
# 配置线程池信息,需要一个实现了org.quartz.spi.ThreadPool接口的类,官方实现的除SimpleThreadPool了之外,还有一个ZeroSizeThreadPool
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
# 线程池数量,至少为1,最好不要超过100
org.quartz.threadPool.threadCount = 10
# 线程优先级,1-10,默认为5
org.quartz.threadPool.threadPriority = 5
org.quartz.threadPool.threadsInheritContextClassLoaderOfInitializingThread = true
# JobStore作业存储
org.quartz.jobStore.misfireThreshold = 60000
# 用于在Terracotta服务器内存储调度信息
org.quartz.jobStore.class = org.terracotta.quartz.TerracottaJobStore
# org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
org.quartz.jobStore.tcConfigUrl = localhost:__PORT__
Terracotta是一种分布式java集群技术,它巧妙得隐藏了多个分布式JVM带来的复杂性,使得java对象能够透明得在多个JVM集群中进行分享和同步,并能够进行持久化。从某种意义上讲它类似于hadoop中的zookeeper,可以作为zookeeper之外的另外一种选择。
2.7. 监听器
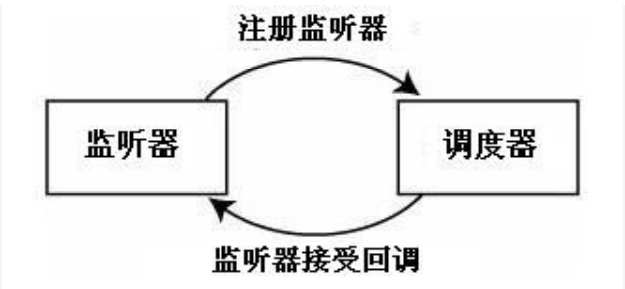
Quartz的监听器有JobListener、TriggerListener、SchedulerListener三种。
监听器有全局和非全局两种,全局监听器能够接收到所有的Job/Trigger事件的通知。非全局只能接受到其上注册的Job/Trigger事件。
在编写监听器之前,不需要事先知道监听器是全局的还是非全局的,因为只在注册的时候会加以区分。仅仅实现了接口和提供了监听器方法即可。
这里看到有新老版本的差异,主要的变动为 scheduler不再负责全局监听器的添加操作,包括JobListener、TriggerListener和SchedulerListener,转而由scheduler.getListenerManager()调出的监听器管理器负责。 且addXXXListener方法传递单参的时候为全局监听器,否则需要传递第二个参数(Matcher对象)
// 添加全局的Job监听 *在源码中已经找不到addGlobalJobListener方法。*
scheduler.addGlobalJobListener(myJobListener);
// 创建并注册一个全局的Trigger Listener
public void addTriggerListener(TriggerListener triggerListener) {
addTriggerListener(triggerListener, EverythingMatcher.allTriggers());
}
scheduler.getListenerManager().addTriggerListener(new MyTriggerListener("simpleTrigger"));
// 创建并注册一个全局的Job Listener
public void addJobListener(JobListener jobListener) {
addJobListener(jobListener, EverythingMatcher.allJobs());
}
scheduler.getListenerManager().addJobListener(new MyJobListener());
// 创建并注册一个局部的Trigger Listener
scheduler.getListenerManager().addTriggerListener(new MyTriggerListener("simpleTrigger"), KeyMatcher.keyEquals(TriggerKey.triggerKey("trigger1", "group1")));
// 创建并注册一个指定任务的Job Listener
scheduler.getListenerManager().addJobListener(new MyJobListener(), KeyMatcher.keyEquals(JobKey.jobKey("job1", "group1")));
// 创建SchedulerListener
MySchedulerListener mySchedListener = new MySchedulerListener()
scheduler.getListenerManager().addSchedulerListener(mySchedListener);
// 删除SchedulerListener
scheduler.getListenerManager().removeSchedulerListener(mySchedListener);
配置全局TriggerListener
org.quartz.triggerListener.NAME.class = com.foo.MyListenerClass
org.quartz.triggerListener.NAME.propName = propValue
org.quartz.triggerListener.NAME.prop2Name = prop2Value
配置全局JobListener
org.quartz.jobListener.NAME.class = com.foo.MyListenerClass
org.quartz.jobListener.NAME.propName = propValue
org.quartz.jobListener.NAME.prop2Name = prop2Value
JobListener
public interface JobListener {
public String getName();
// 执行前执行
public void jobToBeExecuted(JobExecutionContext context);
// 否决时执行
public void jobExecutionVetoed(JobExecutionContext context);
// 执行后执行
public void jobWasExecuted(JobExecutionContext context,
JobExecutionException jobException);
}
TriggerListener
public interface TriggerListener {
public String getName();
// 触发器触发时执行
public void triggerFired(Trigger trigger, JobExecutionContext context);
// 否决时执行
public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context);
// 错过触发时执行
public void triggerMisfired(Trigger trigger);
// 触发完成时执行
public void triggerComplete(Trigger trigger, JobExecutionContext context,
int triggerInstructionCode);
}
SchedulerListener
public interface SchedulerListener {
void jobScheduled(Trigger trigger);
void jobUnscheduled(TriggerKey triggerKey);
void triggerFinalized(Trigger trigger);
void triggerPaused(TriggerKey triggerKey);
void triggersPaused(String triggerGroup);
void triggerResumed(TriggerKey triggerKey);
void triggersResumed(String triggerGroup);
void jobAdded(JobDetail jobDetail);
void jobDeleted(JobKey jobKey);
void jobPaused(JobKey jobKey);
void jobsPaused(String jobGroup);
void jobResumed(JobKey jobKey);
void jobsResumed(String jobGroup);
void schedulerError(String msg, SchedulerException cause);
void schedulerInStandbyMode();
void schedulerStarted();
void schedulerStarting();
void schedulerShutdown();
void schedulerShuttingdown();
void schedulingDataCleared();
}
Matcher
Matcher有很多实现类:
AndMatcher
EverythingMatcher - 全局
NameMatcher - 根据name
GroupMatcher - 根据group
KeyMatcher -根据group
NotMatcher
OrMatcher
StringMatcher
总结
JobListener和TriggerListener都需要有一个name属性,方便广播。
自定义Listener,可以实现上面两个接口,也可以直接继承JobListenerSupport、TriggerListenerSupport和SchedulerListenerSupport抽象类,这类抽象类提前对所有需要实现的方法进行了空实现,只需要继承这类抽象类并重写需要的方法即可。
listener是注册到scheduler的ListenerManager上的,与listener一同注册的还有一个Matcher对象,该对象用于描述listener期望接收事件的job或trigger。
scheduler.getListenerManager().addJobListener(myJobListener, KeyMatcher.jobKeyEquals(new JobKey("jobName", "jobGroup")));listener是在运行的时候注册到scheduler上的,而且不会与job和trigger一样保存在JobStore中。因为listener一般是应用的一个集成点(integration point),因此,应用每次运行的时候,listener都应该重新注册到scheduler上。
调用Job的execute()方法和调用JobListener、TriggerListener的方法的线程是相同的,因此,需要使监听器中的方法的执行时间尽可能短,否则会对性能带来负面影响。
2.8. Job Stores
JobStore 主要是追踪 scheduler 中的"工作数据": jobs, triggers, calendars 等。
RAMJobStore
优点:快,易配置。
缺点:当应用停止(或崩溃)时,所有的调度信息都将丢失 - 这也意味着 RAMJobStore 并不支持 jobs 和 triggers 的“持久性”
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStoreJDBCJobStore
可以与几乎所有的数据库一起工作,它已经被广泛用于 Oracle、PostgreSQL、MySQL、MS SQLServer、HSQLDB 和 DB2。需要依赖JDBC和一个关系型数据库通信。持久性JobStore会用到许多的JDBC特性,包括事务支持、锁和隔离级别等。
首先需要创建一组 Quartz 使用的数据库。你可以在 Quartz 包的"docs/dbTables"目录下找到创建表的 SQL 脚本。需要注意的是:所有的表都是以"QRTZ_“为前缀的(如"QRTZ_TRIGGERS"和“QRTZ_JOB_DETAIL”)。前缀可以是任意值,只要在配置文件中告诉 JDBCJobStore 前缀的值即可。
表创建好后,在配置和使用 JDBCJobStore 之前,还有重要的一步。你需要决定使用哪种事务。如果你不需要将调度命令(如增加和删除 trigger)与其它事务绑定,你可以让 Quartz 通过JobStoreTX来管理事务(这是最常用的选择)。
如果你需要 Quartz 与其它事务一起工作(比如在 J2EE 应用中),你应该使用JobStoreCMT - 在这种情况下,Quartz 会让应用服务器管理事务。
org.quartz.jobStore.class = org.quartz.impl.jdbcjobstore.JobStoreTX org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate org.quartz.jobStore.tablePrefix = QRTZ_ # DataSource 的名字必须在 Quartz 配置文件中定义。 org.quartz.jobStore.dataSource = myDS需要选择 JobStore 使用的 DriverDelegate。DriverDelegate 主要做数据库相关的 JDBC 工作。StdJDBCDelegate 是使用普通的 JDBC 代码(SQL 语句)的一种代理。如果没有与数据库特定的代理,可以尝试使用 StdJDBCDelegate - 我们仅为那些使用 StdJDBCDelegate 有问题的数据库提供了特定的代理。其它代理可以在“org.quartz.impl.jdbcjobstore”包或子包下找到,包括 DB2v6Delegate, HSQLDBDelegate, MSSQLDelegate, PostgreSQLDelegate,WeblogicDelegate, OracleDelegate 等。
如果你的 Scheduler 很忙(比如,总是执行与线程池线程数量一致的 job),可能需要将 DataSource 中连接数的数量设置为线程池大小+2.
TerracottaJobStore
TerracottaJobStore 提供了更好的扩展性和健壮性,且不使用数据库。意味着数据库不需要支持 Quartz 的负载,可以将数据库资源用于应用的其它部分。
TerracottaJobStore 可以运行在集群或非集群模式,在任何一种模式下都可以保证在应用重启时 job 数据的持久化,因为数据是存储在 Terracotta 服务器上。性能比使用数据库高很多(差不多一个量级),但比 RAMJobStore 要慢。
要使用 TerracottaJobStore(假设当前使用的是 StdSchedulerFactory),只需要设置 org.quartz.jobStore.class = org.terracotta.quartz.TerracottaJobStore,并添加额外一行配置指定 Terracotta 服务器的地址:
org.quartz.jobStore.class = org.terracotta.quartz.TerracottaJobStore org.quartz.jobStore.tcConfigUrl = localhost:9510
2.9. 其他
主处理线程QuartzSchedulerThread
Quartz 应用第一次运行时,main 线程会启动 Scheduler。QuartzScheduler 被创建并创建一个 org.quartz.core.QuartzSchedulerThread 类的实例。QuartzSchedulerThread 包含有决定何时下一个 Job 将被触发的处理循环。顾名思义,QuartzSchedulerThread 是一个 Java 线程。它作为一个非守护线程运行在正常优先级下。
QuartzSchedulerThread 的主处理循环的职责描述如下:
当 Scheduler 正在运行时:
A. 检查是否有转换为 standby 模式的请求。
1. 假如 standby 方法被调用,等待继续的信号B. 询问 JobStore 下次要被触发的 Trigger.
1. 如果没有 Trigger 待触发,等候一小段时间后再次检查假如有一个可用的 Trigger,等待触发它的确切时间的到来
D. 时间到了,为 Trigger 获取到 triggerFiredBundle.
E. 使用 Scheduler 和 triggerFiredBundle 为 Job 创建一个 JobRunShell 实例
F. 告诉 ThreadPool 可能时运行 JobRunShell. 这个逻辑存在于 QuartzSchedulerThread 的 run() 方法中。
在1.8版本开始,JobInitializationPlugin被XMLSchedulingDataProcessorPlugin取代。
根据name, group 获取jobkey
public static JobKey jobKey(String name, String group) { return new JobKey(name, group); }暂停Scheduler后恢复,会一次性执行暂停期间的任务。
# 这个时间大于10000(10秒)会导致MISFIRE_INSTRUCTION_DO_NOTHING不起作用。 # 暂停时间在6秒内,会执行暂停中应该执行的任务,超过6秒,则不会执行。 org.quartz.jobStore.misfireThreshold = 6000